Landschapsanalyse van Europese onderzoeksdata
Over het Europese landschap
In de studie ‘European Research Data Landscape’ wordt gekeken naar de werkwijze van onderzoekers bij het produceren, hergebruiken en deponeren van gegevens, en bij het FAIR maken daarvan. Ook wordt gekeken naar het landschap van onderzoeksdata repositories. Tijdens de studie zijn twee enquêtes uitgevoerd – één onder onderzoekers (meer dan 15.000 respondenten) en één onder repositories van onderzoeksdata (meer dan 300 respondenten) – en is een geautomatiseerde evaluatie van de FAIRness van onderzoeksdatasets, met behulp van de F-UJI tool. Uit de bevindingen van de studie blijkt dat, hoewel bepaalde FAIR-praktijken worden toegepast en onderzoekers gemotiveerd zijn door de idealen van Open Science, er nog steeds belemmeringen zijn om FAIR data te maken. Deze betreffen beperkte lokale ondersteuning, de daadwerkelijke implementatie van FAIR in de dagelijkse praktijk, gebrek aan bewustzijn en het ontbreken van controle op vooruitgang op verschillende niveaus.
Resultaten
Behoefte om data te beheren en op te slaan
Er is een aantal voor de hand liggende uitkomsten, zoals dat het beleid van subsidieverstrekkers, instellingen en uitgevers voor de respondenten de meeste invloed heeft als het gaat om het beheer van onderzoeksdata (Research Data Management = RDM) en het delen van data. Respondenten slaan data op verschillende plaatsen op: lokale opslag is iets populairder dan institutionele cloudopslag en persoonlijke fysieke gegevensopslag heeft de voorkeur boven persoonlijke cloudopslag. 40% van de respondenten heeft minimaal één keer een onderzoeksdata repository gebruikt om hun data op te slaan.
De sterkste drijfveren om data in een repository op te slaan zijn ten eerste, met 65%, het versnellen van wetenschappelijk onderzoek en het publieke nut. Ten tweede het verspreiden en voortzetten van impactonderzoek, en ten derde, het ondersteunen van Open Science (58%). Opmerkelijk is dat de opslagvereisten van de uitgevers, subsidieverstrekkers of instellingen met ongeveer 30% lager scoren dan hun beleid voor het beheren en delen van data.
Hoe bekend is FAIR?
Meer dan 60% van de respondenten is tot op zekere hoogte bekend met de FAIR-principes en bijna tweederde van hen geeft aan deze in praktijk te brengen. Het is ook mogelijk dat onderzoekers ‘FAIR-gedrag’ vertonen zonder de principes te kennen, zoals het volgende diagram aangeeft (N=10.889):
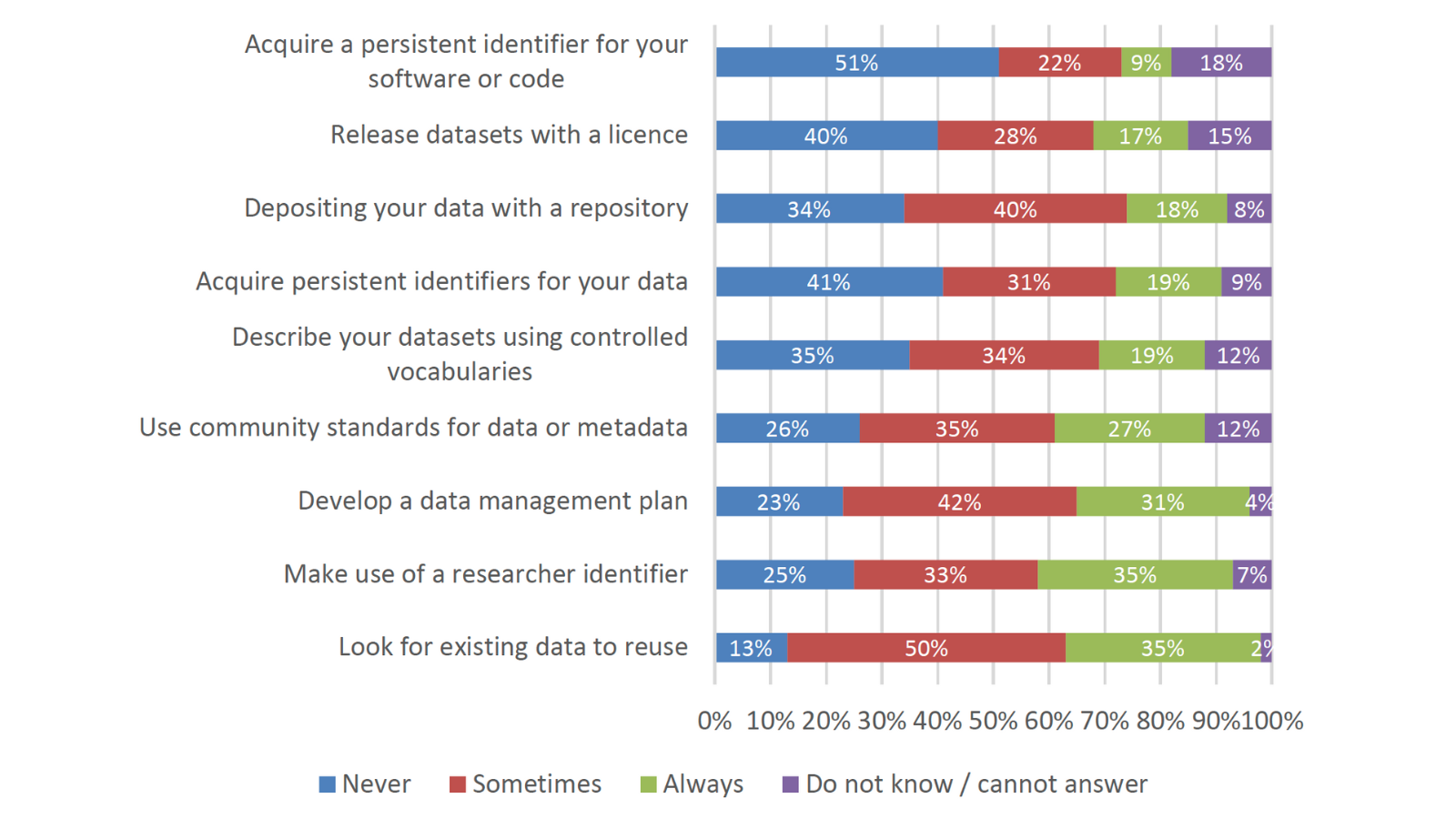
Bijna eenderde van de respondenten gebruikt altijd community-standaarden voor (meta)data, maakt gebruik van een persistent identifier zoals ORCID, ontwikkelt een plan voor databeheer (datamanagementplan = DMP) en zoekt naar bestaande data voor hergebruik. Daar staat tegenover dat veel respondenten nooit een persistent identifier voor hun software of data aanvragen. Onderzoeksinstellingen worden genoemd als de eerste plaats waar men terecht kan voor ondersteuning bij het beheren, delen en/of FAIR maken van data. Daarna volgen het vakgebied en de nationale instanties.
Hergebruik van gegevens
Hoewel veel respondenten niet van FAIR hebben gehoord of data opslaan, lijken de opvattingen achter de principes aan te slaan bij de respondenten (N = 10.900):
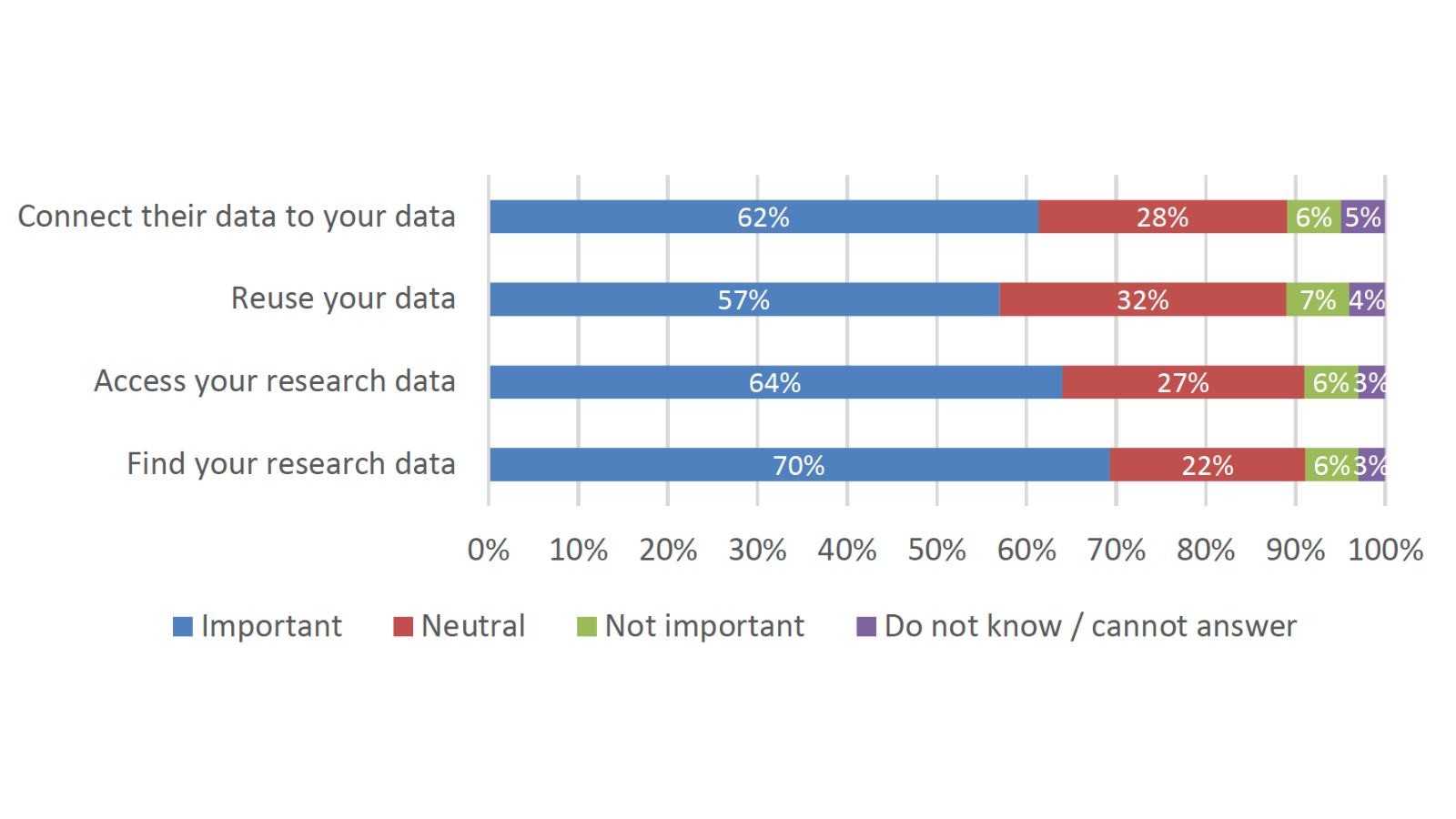
Respondenten die data hebben hergebruikt, hebben meestal data hergebruikt waarnaar in wetenschappelijke publicaties wordt verwezen of data die zij in het verleden al hadden gebruikt. Het was ook vrij gebruikelijk om relevante data te vinden tijdens een open zoekopdracht. Van de 7.738 respondenten die bestaande gegevens hergebruikten, had 68% gegevens hergebruikt die zonder beperkingen openbaar beschikbaar waren.
Hoe FAIR zijn datasets in repositories?
Voor het onderzoek werden bijna 8.000 datasets in 31 repositories in heel Europa automatisch beoordeeld met de ‘F-UJI FAIR metrics assessment tool’. De totale gemiddelde score van deze datasets was 54,6%. Op zich zegt dit percentage niet veel, omdat verschillende beoordelingstools verschillende aspecten op verschillende manieren testen en beoordelen. Bovendien varieert ook de architectuur van repositories, waardoor het voor geautomatiseerde tools lastig kan zijn om specifieke informatie te vinden. Daarom heeft het DANS-team de bevindingen niet alleen in het rapport gepresenteerd en toegelicht, maar ook toegelicht in een workshop met vertegenwoordigers van de betrokken repositories.
Conclusie
Er is nog veel te doen om FAIR en Open Science tot stand te brengen. DANS werkt daar hard aan, zowel op nationaal als internationaal niveau. Bijvoorbeeld met onze Data Stations voor langdurige, duurzame bewaring en toegang, het TDCC-SSH programma om onderzoekers en instellingen in Sociale en Geesteswetenschappen te ondersteunen en FAIR-IMPACT om de FAIR-principes en oplossingen te implementeren.
De studie werd uitgevoerd in opdracht van het directoraat-generaal Onderzoek en Innovatie (DG RTD) van de Europese Commissie, met als algemeen doel een gedetailleerde analyse van het ecosysteem voor onderzoeksdata in de Europese context, die de EU-lidstaten, de met Horizon 2020 Associated Countries (AC) en het VK bestrijkt. De studie werd uitgevoerd door Visionary Analytics, DANS, het Digital Curation Centre (DCC) en het European Future Innovation System (EFIS) centrum. Het volledige rapport met aanbevelingen voor de Europese Commissie en alle onderliggende gegevens zijn beschikbaar via Zenodo.
Heb je vragen over dit bericht?




